Introduction to Web - Detailed Explanation
Introduction to web is necessary step before starting web development journey. You must know about web. So this article you will get understand about the web.
Basics of WWW
World Wide Web, also known as the web, is a collection of websites and web pages stored in web servers and connected to the local computer through the internet. A huge amount of images, documents, and other resources are stored in the server and accessed using hyperlinks. Thus people use the internet through the web.
The Web has a body of software, and a set of protocols and conventions.
History of WWW
Sir Tim Berners-Lee introduced the concept of the WWW at the European Organization of Nuclear Research (CERN). He developed a personal database of people and software models and used hypertext so that each new page details was linked to an existing page.

Sir Tim Berners-Lee
Sir Tim Berners-Lee introduced tools such as HyperText Transfer Protocol (HTTP) between 1989-1991, Web browser in 1990, and HyperText Markup Language (HTML) in 1993.
In 1991, Gopher protocol came up along with HTTP protocol. Which provided access to content through hypertext menus presented as a file system rather than through HTML files.
In 1993, a new web browser with a graphical user interface (GUI) Mosaic browser was introduced.
In 1994, the World Wide Web Consortium (W3C) was founded by Tim Berners-Lee. The World Wide Web Consortium (W3C) is an international community where Member organizations, a full-time staff, and the public work together to develop Web standards.
Led by Web inventor and Director Tim Berners-Lee and CEO Jeffrey Jaffe, W3C’s mission is to lead the Web to its full potential. Contact W3C for more information.
Tim Berners-Lee made the web freely, and then at the end of 1994, a large number of websites got activated with popular web service.
Trade marketing started using WWW during 1996-1998. The term e-commerce got introduced during this period.
During 1998-2000, many entrepreneurs started selling their ideas using dotcom (.com) boom.
From 2000 - till now, the WWW has got an evolving due to various development such as search engines, e-commerce sites, online booking, social medias, blogs, etc.
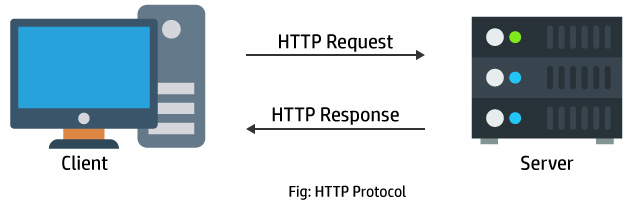
HTTP Protocol
The Hypertext Transfer Protocol (HTTP) is application-level protocol for collaborative, distributed, hypermedia information systems.
It is the data communication protocol used to establish communication between client and server.
Basically it follows the request response model. The client makes the request for the desire website or web page to the server by giving the URL in the address bar in browser. This request is receive by web server and web server gives the response to the web browser by returning required web page.
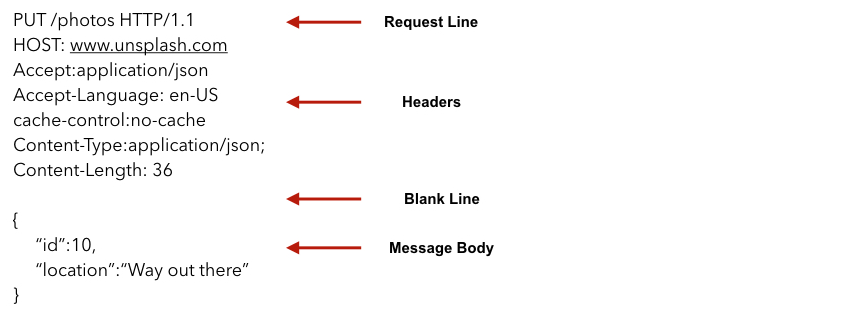
HTTP Request Message Structure
The basic structure of HTTP request message is given by following general form -
<Start line>
<Header field>
<Blank line>
<Message Body>
Let us discuss this structure in more detail.
Start line
The start line consist three more parts which is separated by a single space. Following are parts,
- Request Method
- Request-URI
- HTTP version
1) Request method This method defines the CONNECT method which is used while web browser and server communication. The primary method in HTTP is GET.
There are other methods too, such as POST, PUT, PATCH, HEAD, etc. Various methods are listed here in detail.
| HTTP methods | Description |
| GET | The GET method requests a representation of the specified resource. Requests using GET should only retrieve data. |
| POST | The POST method is used to submit an entity to the specified resource, often causing a change in state or side effects on the server. |
| HEAD | The HEAD method asks for a response identical to that of a GET request, but without the response body. |
| OPTIONS | The OPTIONS method is used to describe the communication options for the target resource. |
| PUT | The PUT method replaces all current representations of the target resource with the request payload. |
| DELETE | The DELETE method deletes the specified resource. |
| TRACE | The TRACE method performs a message loop-back test along the path to the target resource. |
| CONNECT | The CONNECT method establishes a tunnel to the server identified by the target resource. |
| PATCH | The PATCH method is used to apply partial modifications to a resource. |
2) Request URI: Uniform Resource Identifier also known as URI is a string used to identify the resources or name on the Internet.
The URI is a combination of URN and URL. URN means Uniform Resource Name and URL means Uniform Resource Locator.
The web address denotes the URL and the specific name of the place or a person or item denotes URN.
Identifies a resource by name. It always starts with the prefix urn: For example,
urn:isbn:0451450523to identify a book by its ISBN number.urn:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66a globally unique identifier.urn:publishing:book- An XML namespace that identifies the document as a type of book.
Every URI consists of two parts, the part before the colon(:) denotes the scheme and the part after the colon(:) depends upon the scheme.
The URIs are case insensitive and generally written in lower case. If the URI is written in the form of http: then it is both an URI and URL but there are some other URI which can also be used as URL. For example,
| URL | Intended server |
| ftp://ftp.example.com/index.html | file can be located on FTP server |
| telnet://example.com | Telnet server |
| mailto:[email protected] | Mailbox |
| http://www.codesnail.com | Web Server |
3) HTTP version
The first version of HTTP was HTTP/0.9 but then HTTP/1.1 came and now HTTP/2.0 also here.
Header fields and message body
The host header filed is associated with the http request. The header fields are in the form of field name and field value.
HTTP request message structure
HTTP Response Message Structure
The response message structure is similar as request message structure. Just look,
<Status line>
<Header fields>
<Blank line>
<Message Body>
Lets understand in detail.
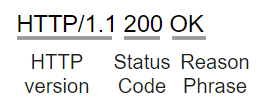
Status line
Status line is very similar to start line of the request message structure. It consists of three fields.
| HTTP version | Status code | Reason phrase |
The HTTP version denotes the HTTP version like HTTP/1.1 or HTTP/2.0. The status code is a numeric code indicating the type of response. The reason phrase is in the text string form and presents the information about the status code. For example,
Following are some commonly used status code,
| Status code | Reason phrase | Description |
| 200 | OK | The request has succeeded. |
| 201 | Created | The request has succeeded and a new resource has been created as a result. This is typically the response sent after POST requests or some PUT requests. |
| 202 | Accepted | The request has been received but not yet acted upon. It is noncommittal since there is no way in HTTP to later send an asynchronous response indicating the outcome of the request. It is intended for cases where another process or server handles the request, or for batch processing. |
| 301 | Moved permanetaly | The URL of the requested resource has been changed permanently. The new URL is given in the response. |
| 401 | Unauthorized | Although the HTTP standard specifies "unauthorized", semantically this response means "unauthenticated". That is, the client must authenticate itself to get the requested response. |
| 403 | Forbidden | The client does not have access rights to the content; that is, it is unauthorized, so the server is refusing to give the requested resource. Unlike 401, the client's identity is known to the server. |
| 404 | Not Found | The server can not find the requested resource. In the browser, this means the URL is not recognized. In an API, this can also mean that the endpoint is valid but the resource itself does not exist. Servers may also send this response instead of 403 to hide the existence of a resource from an unauthorized client. This response code is probably the most famous one due to its frequent occurrence on the web. |
| 500 | Internal server error | The server has encountered a situation it doesn't know how to handle. |
The header field in response message is similar to that of request message. The message body consists of response messag.
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html...
Features of HTTP Protocol
- HTTP is communication protocol used between web browser and web server.
- This protocol is simple and based on request-response messaging. That means client makes the request for required web page and server respond it by sending the requested page or resource.
- HTTP is stateless, but not sessionless, HTTP is stateless, which means there is no connection among two requests being consecutively carried out on the same connection. However, when the core of HTTP is itself a stateless one, HTTP cookies provide in making use of stateful sessions. Through the concept of header extensibility, HTTP cookies can be incorporated into the workflow, making session creation on each HTTP request for sharing the same content.
- HTTP is extensible/customized, HTTP can be integrated with new functionality by providing a simple agreement between a client and a server.
- The request-response message consists of the plain test in fairly readable form.
- The HTTP protocol has a cache control. This is useful feature of HTTP. Most of the web browsers automatically store(cache) the recently visited web pages.
Difference between GET and POST method
| GET | POST |
| In GET method, values are visible in the URL. | In POST method, values are not visible in the URL. |
| GET has a limitation on the length of the values, generally 255 characters. | POST has no limitation on the length of the values since they are submitted via the body of HTTP. |
| GET performs are better compared to POST because of the simple nature of appending the values in the URL. | It has lower performance as compared to GET method because of time spent in including POST values in the HTTP body. |
| This method supports only string data types. | This method supports different data types, such as string, numeric, binary, etc. |
| GET results can be bookmarked. | POST results cannot be bookmarked. |
| GET request is often cacheable. | The POST request is hardly cacheable. |
| GET Parameters remain in web browser history. | Parameters are not saved in web browser history. |
Limitation of HTTP Protocol
- HTTP protocol is not a secured one.
- It is a stateless protocol and therefore can’t remember the previous communication.
- HTTP is a text-based protocol. Hence the communication is readable to anybody.
Some quetions-answer
Why HTTP is called as stateless protocol?
Ans: HTTP protocol can not remember previous user’s information not it can remember the number of times user has visited a particular website. That’s why it is a stateless protocol.
Explain following HTTP command,
GET /index.html http/1.0
Ans: GET - This is the http method to use retrieve information from a specied URI and is assumed to be safe, repeatable operation by browser.
The index.html is the file that requested by user from web browser.
HTTP/1.0 is the http protocol version.
Client Server Architecture
An N-Tier Application program is one that is distributed among three or more separate computers in a distributed network.
N-Tier architecture can be 2-tier, 3-tier or multi-tier architecture.
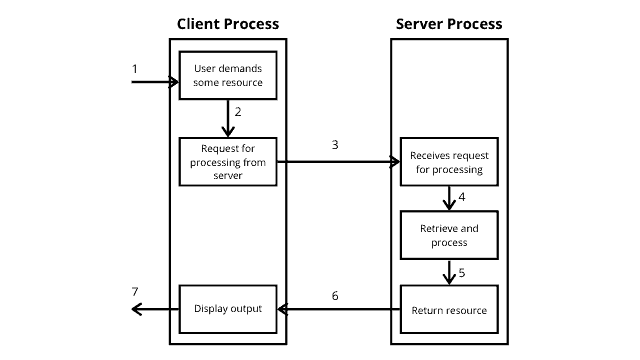
2-tier Architecture
It is like Client-Server architecture, where communication takes place between client and server.
In this type of software architecture, the presentation layer or user interface layer runs on the client-side while the dataset layer gets executed and stored on the server side.
There is no Business logic layer or immediate layer in between client and server.
2-tier architecture
3-tier Architecture
3-tier architecture has three different layers.
- Presentation layer
- Business logic layer
- Database layer
So, this architecture has 3 components
- Client PC
- Application server
- Database server
In 3-tier architecture the work of server is distributed among application server and databases servers.
Application server possess the required communication functions. The data required by this business logic is present on database server. The required data is returned to application servers and then to client machine/PC.
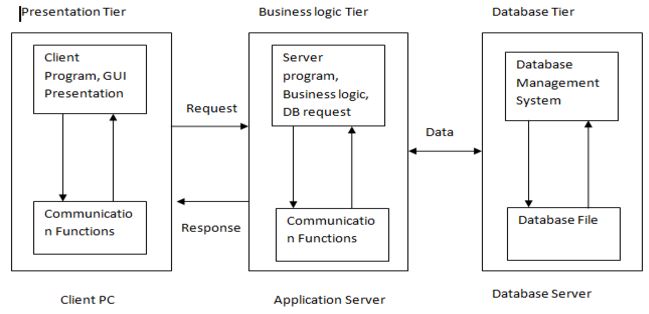
3-tier architecture
Multi-tier Architecture
Various components are there in Multi-tier architecture to help in handling web request very effectively. components like,
- Clinet PC (obviously)
- Application server
- Distributed components (CORBA)
- Connectors
- HTTP server
- Web services, EJB containers, JDBC, JAVA IDL, and so on.
- Databases
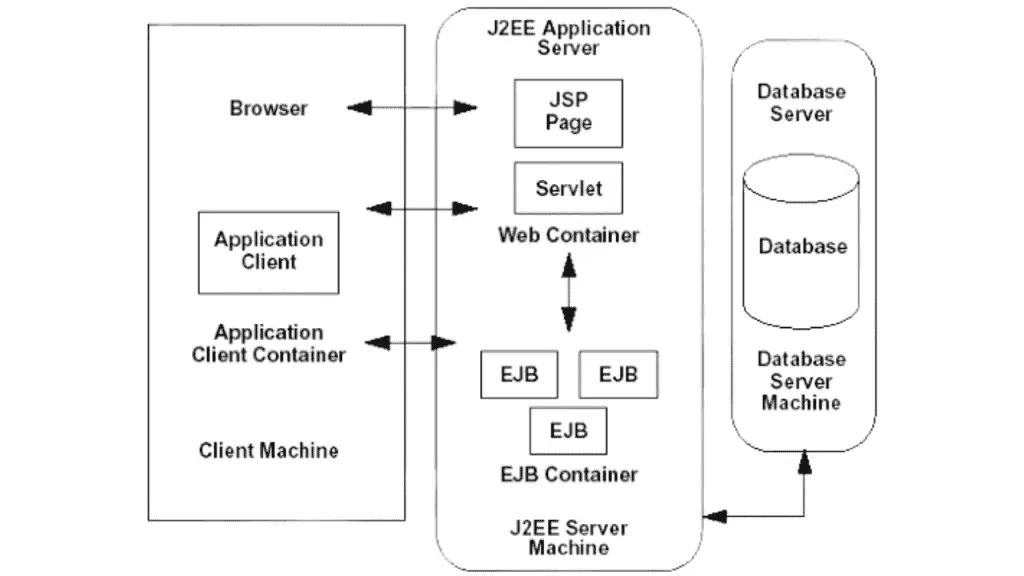
N-tier architecture
Advantages
- Scalability
- Data Integrity
- Reusability
- Reduced Distribution
- Improved Security
- Improved Availability
Disadvantages
- Increase in Effort
- Increase in Complexity
Web Browser
A browser is a software program that is used to explore, retrieve, and display the information available on the World Wide Web.
This information may be in the form of pictures, web pages, videos, and other files that all are connected via hyperlinks and categorized with the help of URLs (Uniform Resource Identifiers). For example, you are viewing this page by using a browser.
A browser is a client program as it runs on a user computer or mobile device and contacts the webserver for the information requested by the user.
The web server sends the data back to the browser that displays the results on internet supported devices. On behalf of the users, the browser sends requests to web servers all over the internet by using HTTP (Hypertext Transfer Protocol). A browser requires a smartphone, computer, or tablet and internet to work.
Various browsers are available in market, like Google Chrome, Mozilla Firefox, Opera, Safari, Internet explorer, etc.
I’m sure, you very much familiar with the browser because you are accessing this content through the browser.
There are various languages available to display the web pages and content on the web browser. Like HTML right.
Function defined by Web Browser
Many functions of web browsers are-
- Reformat the URL and send the valid HTTP request on Internet.
- When user gives the URL address of particular domain then web browsers helps converts the DNS to corresponding IP address.
- Web browser helps establishes the connection with web servers and client.
- The web browsers send the HTTP request to the server.
- Web browsers display the web pages that request by client.
- Web browsers automatically store (Cache) the recently visited web pages. This feature is called Cache control.
Web Browser Architecture
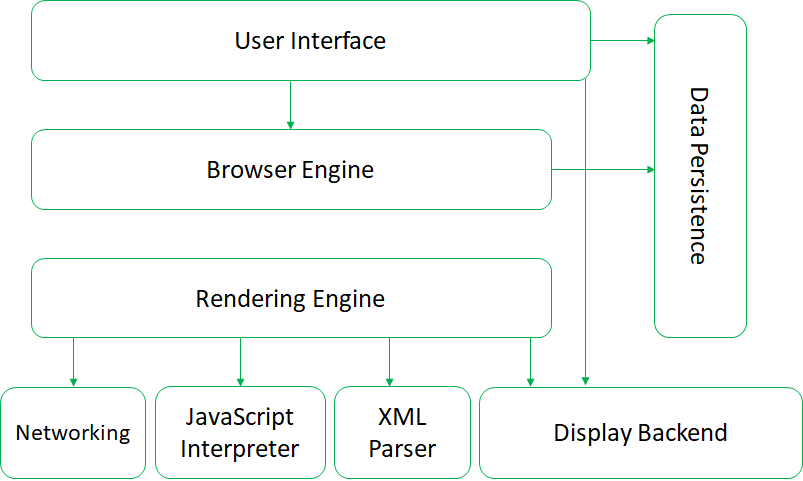
Architecture of web browser
User Interface: The User Interface subsystem is the layer between the user and the Browser Engine. It provides features such as toolbars, visual page-load progress, smart download handling, preferences, and printing.
It may be integrated with the desktop environment to provide browser session management or communication with other desktop applications.
Browser Engine: The Browser Engine subsystem is an embedded component that provides a high-level interface to the Rendering Engine(Which is the next layer).
It loads a given URL and supports primitive browsing actions such as forward, back, and reload.
It provides hooks for viewing various aspects of the browsing session such as current page load progress and JavaScript alerts. It also allows the querying and manipulation of Rendering Engine settings.
Rendering Engine: The Rendering Engine subsystem produces a visual representation for a given URL. It is capable of displaying HTML and Extensible Markup Language (XML) documents, optionally styled with CSS, as well as embedded content such as images.
Networking: The Networking subsystem implements file transfer protocols such as HTTP and FTP
JavaScript Interpreter: The JavaScript Interpreter evaluates JavaScript code, which may be embedded in web pages.
XML Parser: The XML Parser subsystem parses XML documents into a Document Object Model (DOM) tree.
This is one of the most reusable subsystems in the architecture. In fact, almost all browser implementations leverage an existing XML Parser rather than rewriting their own from scratch.
Display Back-end: The Display Back-end subsystem provides drawing and windowing primitives, a set of user interface widgets, and a set of fonts. It may be tied closely with the operating system.
Data Persistence: The Data Persistence subsystem stores various data associated with the browsing session on disk. This may be high-level data such as bookmarks or toolbar settings, or it may be low-level data such as cookies, security certificates, or cache.
Well, architecture may change according to the new technology.
Web Server
Web server is a computer where the web content is stored. Basically web server is used to host the web sites but there exists other web servers also such as gaming, storage, FTP, email etc.
Web site is collection of web pages while web server is a software that respond to the request for web resources.
Web Server Operations
Web server software is accessed through the domain names of websites and ensures the delivery of the site’s content to the requesting user.
The software side is also comprised of several components, with at least an HTTP server. The HTTP server is able to understand HTTP and URLs.
As hardware, a web server is a computer that stores web server software and other files related to a website, such as HTML documents, images, and JavaScript files.
When a web browser, like Google Chrome or Firefox, needs a file that’s hosted on a web server, the browser will request the file by HTTP.
When the request is received by the web server, the HTTP server will accept the request, find the content and send it back to the browser through HTTP.
More specifically, when a browser requests a page from a web server, the process will follow a series of steps.
First, a person will specify a URL in a web browser’s address bar. The web browser will then obtain the IP address of the domain name — either translating the URL through DNS (Domain Name System) or by searching in its cache.
This will bring the browser to a web server. The browser will then request the specific file from the web server by an HTTP request.
The web server will respond, sending the browser the requested page, again, through HTTP. If the requested page does not exist or if something goes wrong, the web server will respond with an error message. The browser will then be able to display the webpage.
Multiple domains also can be hosted on one web server.
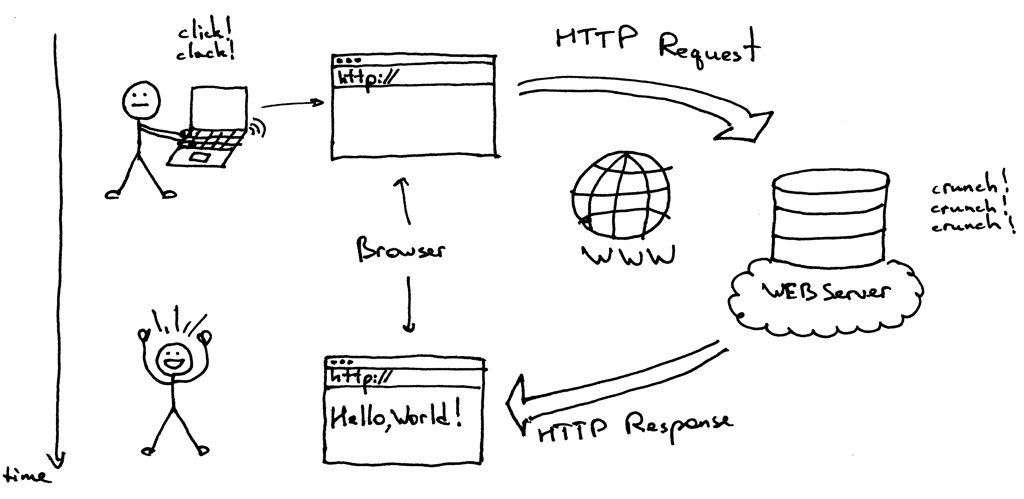
image source: hackernoon
General Server Characteristics
- Web servers have two separate directories document root and server root. These directories and the subdirectories store the software required for server execution.
- Document root directory files are available to the client using the top-level URL. Normally the clients do not access document root directly.
- The server stores the documents that are accessible (readable) to the client outside the document root.
- The virtual document trees are the areas from which the server can serve the document to the client.
- The client can refer to web documents using URL if the documents are stored in subdirectories with the particular file path to a directory from the document root directory.
- Some servers allow access to the web documents or pages that are in the document root of other machines. Such servers are called proxy servers.
- Web servers support various different protocols like HTTP, FTP, Gopher, etc.
- All the web server can interact with the database systems with the help of Server-side scripting and Common Gateway Interface (CGI).
Apache
An Apache Server is a web server application that delivers content such as HTML pages, multimedia and CSS Style sheets over the internet.
Apache is a community-developed web application published by the Apache Software Foundation.
It is arguably the most popular web server software available on the World Wide Web and is most commonly found on Unix based operating systems such as Linux, OSX, Solaris and FreeBSD.
Apache is open source, and as such, it is developed and maintained by a large group of global volunteers. One of the key reasons Apache is so popular is that the software is free for anyone to download and use
IIS
The Internet Information Services or Internet Information Server is a kind of web server provided by Microsoft. This server is most popular on Windows platform.
Difference between Apache and ISS servers
| Apache | ISS |
| Apache can be used on a variety of operating systems such as Mac, Linux, and Windows, etc. | The IIS is only available for the Windows Operating System |
| In Apache's case, almost all of its support is provided by the user community. | The IIS has its own help desk to fix the issues |
| Open-source | It is a vendor-specific product and can be used on windows products only |
| The Apache web server can be controlled by editing the configuration file httpdp.conf | For IIS server, the behavior is controlled by modifying the window based management programs called IIS snap-in. We can access ISS snap-in through the Control-panel->Administrative Tools. |
Functions of Web Server
- The primary task of the webserver is to monitor the communications port on the host machine. It accepts the HTTP command using this port and performs the operation specified by the commands.
- Besides this primary task, web servers support more than one site on a computer potentially reducing the cost of each site and making their maintenance more convenient.
- There is a concept of proxy server intended to provide more services of the webserver. The proxy server is a server that serves the requests made by the clients by forwarding those requests to the corresponding servers. The proxy servers sometimes can alter the clients’ requests. The proxy servers are mostly used to control, monitor, or unbound the network traffic. Some proxy servers cache the requested data. This helps in a quick serving of the request when the demand for the previously read data is made. Using Proxy server setting an organization can block certain sites so that controlling network traffic can be possible.
- Although web servers were originally designed to support HTTP protocol, there are web servers that support FTP, Gopher, News, and mail, protocols.
Introduction to Web Server Installation and Configuration.
Apache web server is an open-source product and it is available on the internet for free. You can get it downloaded from the site https://httpd.apache.org/download.cgi
click on this link to see how to install Apache
- for windows 7: https://www.webdevelopersnotes.com/install-apache-windows-7
- for windows 10: https://www.thewindowsclub.com/install-apache-on-windows-10
- for Linux: https://www.guru99.com/apache.html
Also we will see installation of xampp in php tutorial.
Hope you like this introduction to web. Share it with your friends.
Also check,